This article will most probably be updated a few times; I have seriously downloaded hundreds of scientific articles from Google Scholar on the subject of DevOps, MLOps, AIOps and LLMOps and am not even done with 10% of these. Why would I do snow in on these subjects one might ask? I wanted to know how I could learn from my TailSense migration exercise (which I used Claude Code for) and usage of LLMs, machine learning and automate updates, tests and deployments. I also figured it might come in handy in future consultancy assignments in the field of LLM:s. Below is a summary of my findings (so far).
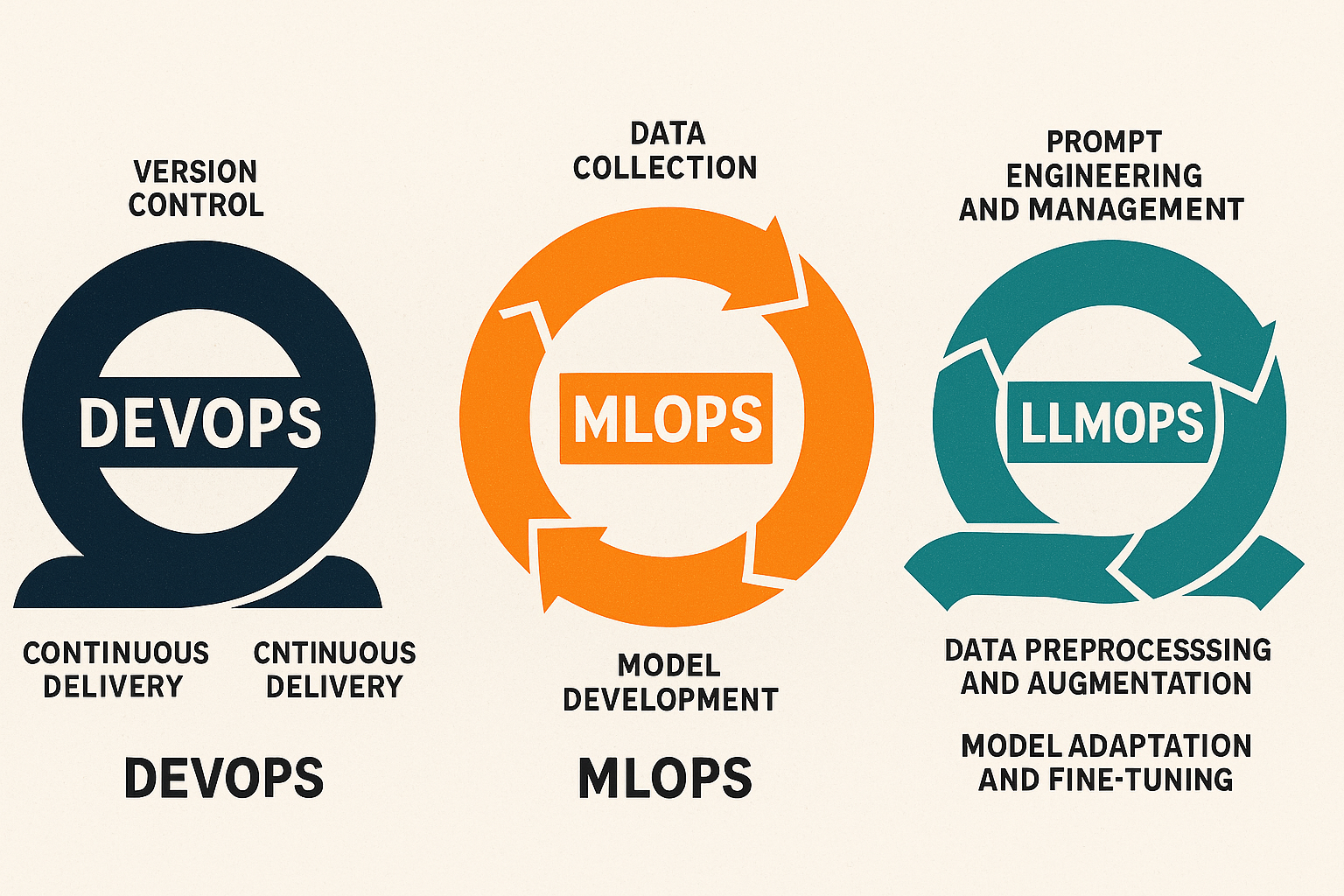
DevOps
DevOps is an abbreviation of Development and Operations. The concept is an extension of agile methodologies that development teams started using around the early 2000s; it addresses the issue of one or maybe both teams being agile, but not necessarily the hand-off or full circle of the development/testing/deployment chain. Development and operations teams might also have different goals, where the first traditionally favors change, the latter stability.
But I haven’t answered the question of what DevOps is yet; well, in short, it’s a software development strategy that bridges the gap between development and operations teams.
The DevOps stages consist of:
- Version control
- Continuous integration (e.g. using software such as Jenkins)
- Continuous delivery
- Continuous deployment (e.g. via docker)
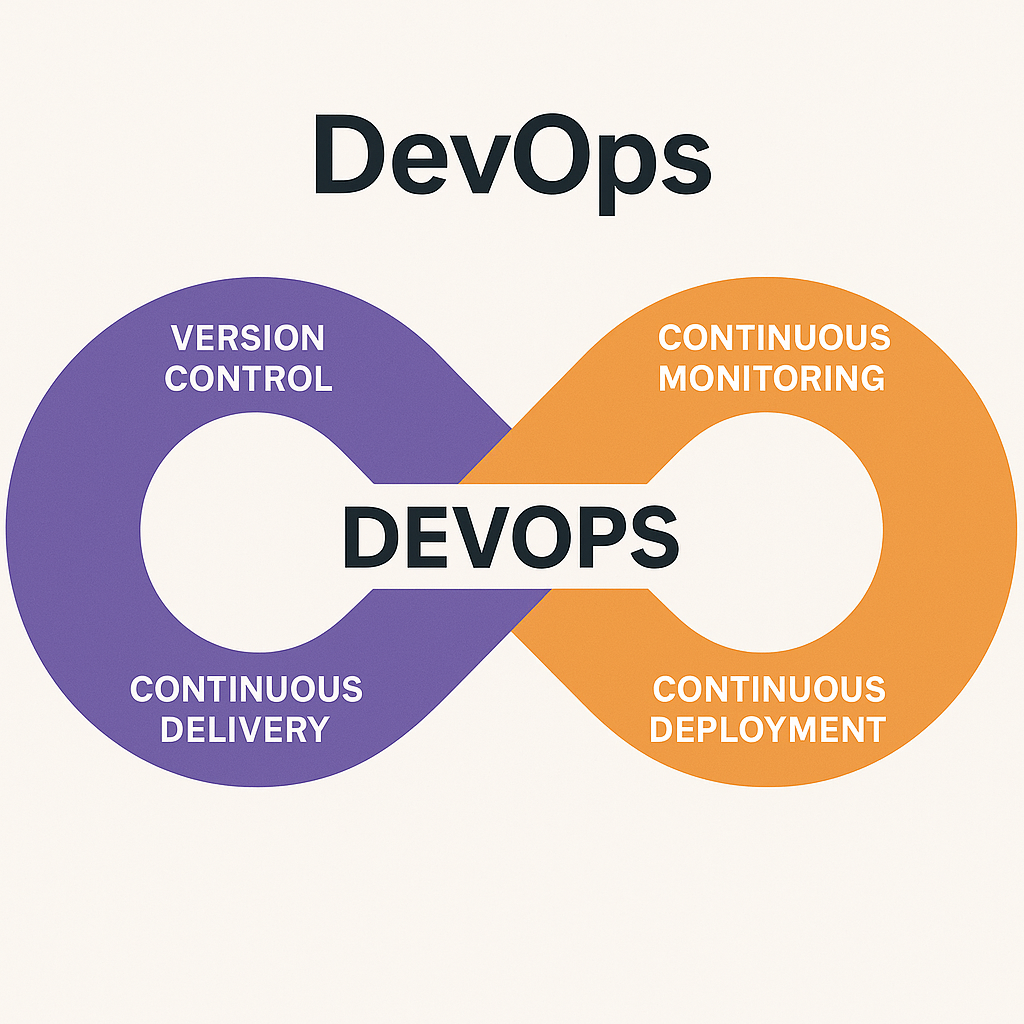
Continuous monitoring should probably be there somewhere in the list above. Let’s go through what this means in turn:
- Version control: being able to save different versions of your work and going back to an old version if needed (e.g. if you make a mistake). It’s also essential when working with others, to avoid overwriting each other’s work; the version control part comes in and merges the team’s work for them.
- Continuous integration: developers are required to commit (i.e. save) changes to a centralized repository (read: server).
- Continuous delivery: deploy to test server and conduct acceptance tests.
- Continuous deployment: after testing, deploy to production server for release to end users.
- Continuous monitoring: e.g. Security Information (SIEM). Report and respond to attacks made on the organization’s infrastructure.
DevOps is basically executing the above continuously, and preferably having the process automated using various software solutions that interact using API:s (Application Programming Interfaces, basically a way for different software to interact).
MLOps
MLOps (Machine Learning Operations) transfers DevOps guidelines to the requirements of managing the machine learning lifecycle[1].
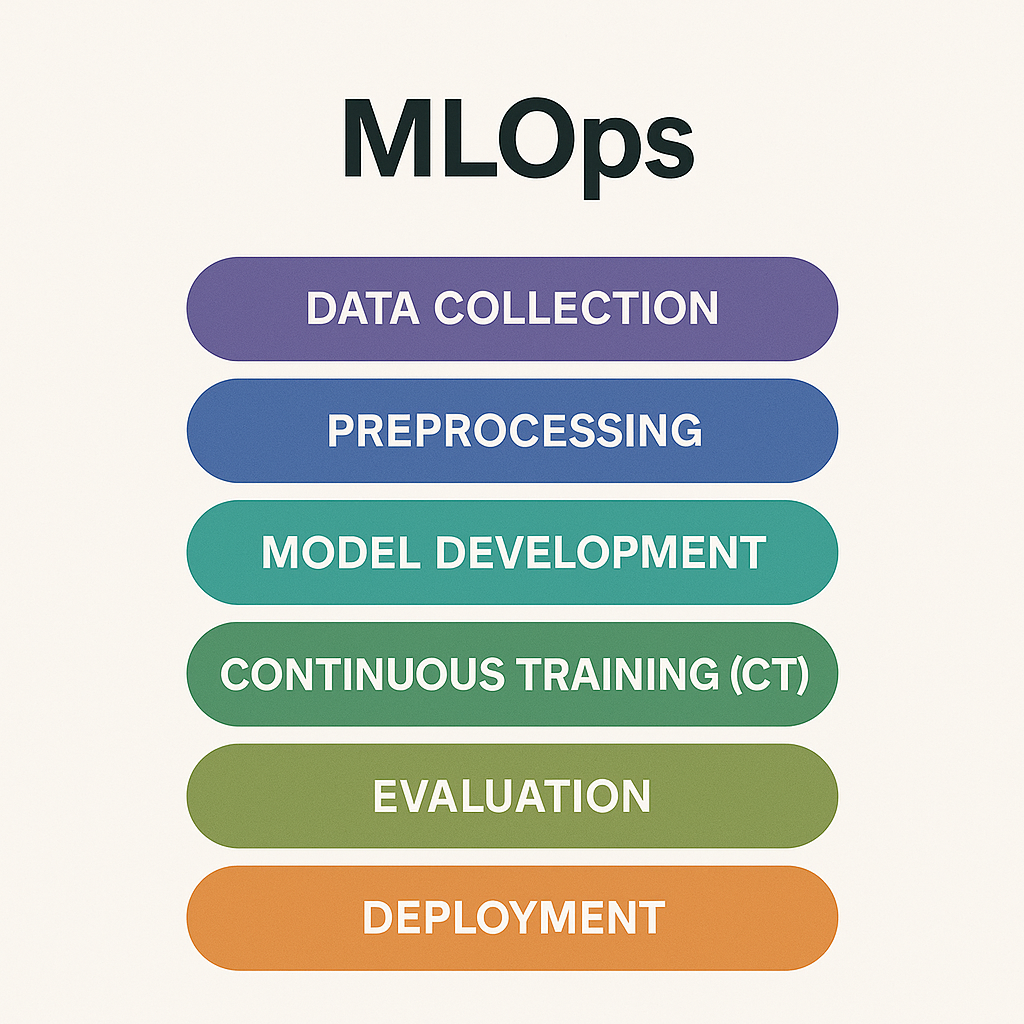
A machine learning model can and will probably become old and stale (due to so called model decay) pretty quickly, and we must add the following steps to the DevOps strategy to keep it as relevant, safe and error free as possible:
- Data collection: gather new and more relevant data when needed
- Preprocessing: clean new data, adapt old
- Model development: automate the creation and adaptation of new variables (automated feature engineering), conduct experiments, create new categories and possibly new mathematical models.
- Continuous Training (CT): a practice that involves updating a model with new data or tasks overtime, without forgetting previously learned knowledge.
- Evaluate the modified model using new input
Open-source solutions you can use for MLOps include MLflow, Kubeflow, ZenML, Metaflow, MLRun and probably a bunch more.
As with all strategies, the choice of ML strategy depends on what is important to the organization or team, e.g. performance vs. innovation/flexibility.
LLMOps
Large Language Models introduce a whole new level of complexity to the DevOps pipeline, due to the fact that we end users do not have access to the source code of these LLM:s and cant prompt these in a way that ascertains a predictable outcome if run continuously and in an automated process.
Technically, we are talking about prompt engineering, dynamic embeddings and integration vector databases, handling token costs, testing with or without human-in-the-loop and security; these terms are basically related to how LLMs consume data, their cost and how humans are involved in their output.

The LLMOps part of the DevOps lifecycle can be described as:
- Prompt engineering and management: creating prompts and setting parameters that result in a desired outcome that is repeatable. In this context, I am assuming you are using LLM API:s (e.g. Open AI API), where you can set your own parameters, e.g. the variable that controls the amount of "so-calledy" of a model (more creativity = higher risk of so called hallucination, or LLMs "making s*** up").
- Data preprocessing and augmentation: collecting and preparing data using internal and/or external data most likely with retrieval-augmented generation, RAG. RAG is taking the LLM beyond the pre-trained data it was trained on and subjecting it to new data, e.g. from the web, a database, PDF files etc.
- Model adaptation and fine-tuning: optimizing the LLM:s for specific tasks.
- Evaluation: assessing quality and performance, by monitoring hallucinations, bias and tracking KPI:s; the latter is rather difficult given the randomness of LLM outputs.
- Deployment: integrating the trained LLM into the existing IT infrastructure
- CI with human involvement: integrate human involvement into the model’s training and improvement.
Case example - TailSense
To make the above less abstract, let’s look at a concrete scenario that ties DevOps, MLOps and LLMOps together in the real world—specifically through the TailSense migration project that I carried out in October 2025.
Background
TailSense originally relied on a WordPress stack with plugin-driven affiliate logic, limited version control, and manual content updates. Price feeds, SEO modules, theme updates and security patches were handled in an ad-hoc fashion and often required direct production edits.
The migration objective was to modernize the tech stack (I hade a PageSpeed of <60), flexibility and control in updating the front-end and back-end and above all else: to automate the process of updating and deploying code.
I realized I need - * drumrolls* - some kind of DevOps strategy in place. The practicalities of using Claude Code to conduct the migration is detailed in a separate article. The below will focus on how I implemented LLMOps to daily work of managing TailSense.
Applying DevOps
The first transformation involved introducing basic DevOps:
| Step | DevOps capability | Practical changes |
|---|---|---|
| 1 | Version control | GitHub with separate dev and main branch |
| 2 | Continuous Integration (CI) | Started committing continuously, several times a day; this practice saved me and TailSense many a time from minor errors to database deletion (long story short, Claude Code went rogue – a story for a separate article). |
| 3 | Continuous Delivery (CD) | Separate dev/test/production databases for testing and deployment. Using automated dry-runs and live runs on the test database. Lastly, a manual human-as-a-judge test using localhost (basically testing locally on your computer). |
| 4 | Continuous Deployment | Pushing to main; errors in build are flagged instantly in the terminal and via email to admin (eh, meaning me). The deployment to production is only conducting if all checks are successful. |
| 5 | Continuous monitoring | The code includes security checks (e.g bots hijacking clicks), and logging of anomalies when the production database is updated. Both AI adapted (Json) and "human friendly" reports (markdown files with stats) are created. Track prompt quality and updating Claude Code's "instruction files" when needed. |
Suddenly, TailSense updates were no longer "manual work when Amira had time" to every day at a specific time from a dedicated Ubuntu server (read: super cheap Lenovo computer. I mean it works).
Every code change became: traceable → testable → reversible and well, professional.
Introducing MLOps
LLMs where as you saw already sneaked into the DevOps process by design. As mentioned above, I had issues with bots hijacking clicks; after an insame amount of nerdy research into the topic, I used Claude Code to implement a system to mitigate this using supervised machine learning for anomaly detection (supervised as in I had a category of "good kind of clicks", and "bad kind of clicks").
Admittedly, I haven’t set the "continuous" part of this yet, but its in the works.
LLMOps necessity
None of the continuous, both manual and automated parts of testing, maintaining, updating and monitoring TailSense development and operations would be possible without LLM:s; I cant clone myself, and I do not have all the skill sets needed (have you seen me design something? I passed art classes in high school because I got a perfect grade on the theory part … lets leave it at that).
Claude Code does:
- Refactoring (meaning changing, amending) code when needed
- RAG for database library querying
- Automated dry-run and live run test
- Carrying out feed updates automatically on a daily basis
- Logging and report creation
"Quirks" such as hallucinations became operational variables I could test and control for with the human-as-a-judge phase / human validation for flagged cases. Prompts where treated as code, and the LLM had a library of guiding "principles" (files such as CLAUDE.md, PLAN.md, DAILY-ORCHESTRATOR.md) to utilize prior to carrying out its instructions. With the daily stats reports I get, I see the KPI:s and quality level of data added to TailSense. Compliance went from non-existing to being continuous and of good quality (surprisingly good, actually).
Key lessons learned
I own TailSense, and could control the implementation (so zero bureaucracy or politics in the way) which helped me iterate and pivot continuously. I didn’t implement DevOps/MLOps/LLMOps because an expensive consultant told management its awesome sauce; I did it out of pure necessity. I cant clone myself, I lack certain skills. I researched, presented myself with a hypothesis, brainstormed it with ChatGPT and Claude Code, then created a plan. Tested, failed, iterated, cried, succeeded, learned and adapted.
I can assure you, not working with a given structure as the one a development and operations strategy gives would have entailed me still being stuck in the broken WordPress solution I had before, not with a fully functional new platform implemented in a few weeks.
Stay tuned—next update will include architecture diagrams and referenced frameworks. You can sign up to my newsletter in the meantime by e-mailing me (you either have my email address or you don’t).
[1] "Engineering Scalable and Adaptive AI Systems: An MLOps-Driven Framework for Innovation in Intelligent Applications", Yeswanth Mutya, Shashank Majety, International Journal of Innovation Studies